Les erreurs, ça arrive
- Publié le
- Temps de lecture estimé à 22 minutes
- Développement, Performances, UX, Web
- css, html, php, symfony, wordpress
Commençons donc par un peu de contexte:
Vous êtes dans le métro parisien, vous devez aller d’un bout à l’autre de la ligne 8.
Le réseau cellulaire est instable, il y a du Edge, de la 3G, de la 4G et votre mobile tente désespérément de rester accrocher au réseau précédent lors des changements d’antenne réguliers.
50 minutes de connexion instable…
Ça vous donne la chair de poule ? C’est pourtant le quotidien de milliers de personnes et peut-être même le votre.
Cela signifie que ces personnes sont régulièrement confrontées à des pertes de connexion ou des micros coupures interrompant partiellement voir totalement le chargement d’une page.
Ici on ne va donc pas parler des éventuelles fautes de frappe que l’on fait tout le temps, ni du fichier que l’on a oublié d’inclure mais des erreurs inévitables dans la vie d’un site internet avec lesquelles on doit composer.1
Bien trop souvent on développe en partant du principe que cela va fonctionner exactement comme on l’a imaginé, parce qu’après tout, c’est le but. Malheureusement il arrive que l’on soit confronté à des problèmes liés à l’environnement de l’utilisateur (sa connexion), à ses actions (mauvaise saisie de formulaire), aux interconnexions (webservices) ou encore simplement la perception des erreurs.
Il s’agit quasi systématiquement d’améliorer l’expérience utilisateur (UX), ou tout du moins de ne pas la détériorer.
Avant les erreurs réelles, commençons par la perception.
Bien que les connexions mobiles soient de plus en plus rapides, la couverture réseau ou l’endroit où l’on se trouve (metro) ralentissent le chargement d’une page.
Fonts
Bien: Famille de police dans CSS
Admettons que vous utilisiez sur votre site une police de caractères non-système sur la totalité de vos textes.
Si vous chargez par exemple une police depuis Google Fonts, et que celui-ci tombe pour une raison ou pour une autre, votre navigateur va donc basculer sur une police système de façon à afficher tout de même le texte.
Si vous n’avez pas défini de police système ou famille de police comme solution de repli (fallback), le navigateur prendra sa police par défaut, ce qui peut fortement dénaturer le design de votre site.
Lorsque vous choisissez une police personnalisée, faites en sorte de trouver l’alternative système la plus proche, puis la famille de police.
Si vous avez choisi une police personnalisée de type Cursive (ce qui est cependant à éviter pour du long texte) et que votre texte s’affiche d'abord avec une police à chasse fixe (monospaced), cela va complètement dénaturer votre charte graphique.
Vous pouvez vous aider d’une liste des polices systèmes les plus déployées pour trouver l’alternative la plus proche.
font-family: 'Open Sans', Arial;
Enfin, il reste la famille de police à mettre, qui laisse votre navigateur choisir parmi celles disponibles sur votre système (et peut donc varier d’un système à l’autre).
En l’occurrence, si vous choisissez délibérément de mettre « Monaco » comme police de caractères, n’oubliez pas de préciser « Monospace » comme famille de police alternative.
Exemple
Ici, avant la famille de police, on met la police Consolas comme alternative système, particulièrement répandu sur Windows.
font-family: monaco, Consolas, monospace;
Vous auriez également très bien pu mettre 'Courier Sans' comme alternative avant monospace.
Si vous incluez une police depuis Google Fonts, regardez le code CSS fourni dans la partie « Specify in CSS », ils donnent systématiquement la famille de police qui convient.
Avec ça, vous assurez déjà un fallback en cas d’échec de chargement de la votre police principale.
Cela ne s’applique d’ailleurs pas forcément qu’à une police personnalisée externe, vous pouvez très bien choisir de charger une police système qui n’est que sur macOS, puis en police secondaire une police qui est sur tous les sytèmes.
Mieux: CSS Font Loading API
Admettons maintenant que vous ayez choisi une police Google Fonts, et que vous ayez chargé celle-ci dans votre HTML accompagné des attributs defer et async :
<link defer async href="https://fonts.googleapis.com/css?family=Open+Sans" rel="stylesheet">
Cela signifie que le contenu de votre page, et certainement votre feuille de style, seront chargés avant la police elle-même, alors que vous avez spécifié dans votre CSS de l’appliquer sur tout le texte de la page.
Tant qu’elle ne sera pas chargée, il y aura donc de fortes chances pour que votre texte n’apparaisse tout simplement pas jusqu’à ce que la police soit disponible, au moins jusqu’au timeout par défaut du navigateur.
Actuellement, le timeout des navigateurs avant de basculer sur la police fallback est le suivant2 :
| Navigateur | Timeout | Fallback | Swap |
|---|---|---|---|
| Chrome 35+ | 3 secondes | Oui | Oui |
| Opera | 3 secondes | Oui | Oui |
| Firefox | 3 secondes | Oui | Oui |
| Internet Explorer/Edge | 0 secondes | Oui | Oui |
| Safari | No timeout | N/A | N/A |
Pour tous ces navigateurs (à l’exception d’IE/Edge), votre texte ne sera pas visible pendant les 3 premières secondes de chargement de la page tant qu’elle n’est pas disponible. Au delà, cela basculera sur la police fallback, puis cela pourra rebasculer sur la police voulue si celle-ci est finalement chargée.
Néanmoins, à mon sens, tous devraient se comporter comme IE/Edge. Imaginez que votre page mette 500ms à charger, mais que pour une raison obscure, la police côté Google mette plus de 3 secondes. Cela signifie que tout le contenu de votre page est quasi immédiatement disponible, mais l’utilisateur devra tout de même attendre au minimum 2,5 secondes supplémentaires pour pouvoir le lire.
Heureusement, une propriété CSS4 permet de modifier ce comportement : font-display.
Grace à cette méthode, vous pouvez définir comment devra se comporter le navigateur tant que la police n’est pas chargée, puis une fois qu’elle est chargée, parmi les modes disponibles.
L’idée ici n’est pas d’en faire un tutoriel complet, on va donc juste se pencher sur 2 valeurs possibles :
optional: Blocage extrêmement court, pas d’échange.
La valeur idéale, car vous évitez le FOUT/FOIT/FOFT. À privilégier, et facile à mettre en place si c’est pour vous, ou que vous êtes le client final. Si vous êtes en agence, il vous faudra convaincre votre client, ce qui sera plus compliqué car la première fois qu’il visitera la page, si la police n’est pas chargée pendant le temps de blocage, il restera sur le fallback jusqu’au rechargement de la page (ou le fait d’aller sur une autre page, puisque la police sera désormais en cache).-
swap: Pas de blocage, période d’échange infinie.
Celle-ci sera plus simple à mettre en place, puisque le fallback est immédiatement affiché, puis remplacé par la bonne police dès que celle-ci est chargée. Cela peut néanmoins déranger puisque la police peut changer à tout moment, en particulier lorsque vous lisez un long texte comme cet article.
De mon point de vue, l'idéal serait finalement pas de blocage, mais une courte période d'échange. Le paramètre qui s'en rapproche le plus est alors fallback.
Le support de cette propriété n’est malheureusement pas encore géré par tous les navigateurs, mais cela est arrivé il y a peu de temps en Technology Preview dans Safari, et depuis la version 58 dans Firefox. J’ai donc bon espoir pour que ce soit implémenté d’ici 2018 dans Edge.
Néanmoins, cette propriété rentrant parfaitement dans le cadre de l’amélioration progressive, je vous recommande vivement de la mettre en place dès maintenant.
Enfin, si vous voulez mettre en place un comportement similaire même sur les navigateurs ne prenant pas en charge cette propriété, vous pouvez coupler l’API CSS.supports()3 de manière à détecter le support de font-display, avec FontFaceObserver afin d’appliquer un comportement similaire à la propriété.
Images
Bien: Balise alt remplie
Passons maintenant aux images. Vous connaissez le refrain, celui sans cesse répété mais pas encore assez appliqué: mettez un texte alternatif à vos images de contenu4.
Oui je précise « de contenu », car une image servant au design (même si ça devrait être en CSS) ne devrait pas avoir de texte alternatif. En effet, savoir que l’image contient un demi-cercle servant à la forme d’un div n’a aucune intérêt pour l’utilisateur se servant d’un lecteur d’écran par exemple.
En revanche, si votre image contient du texte pertinent pour l’utilisateur, vous devez remettre ce texte dans la balise alt de votre image.
Prenons l’exemple du site Oui.sncf et de sa bannière en haut de page5.
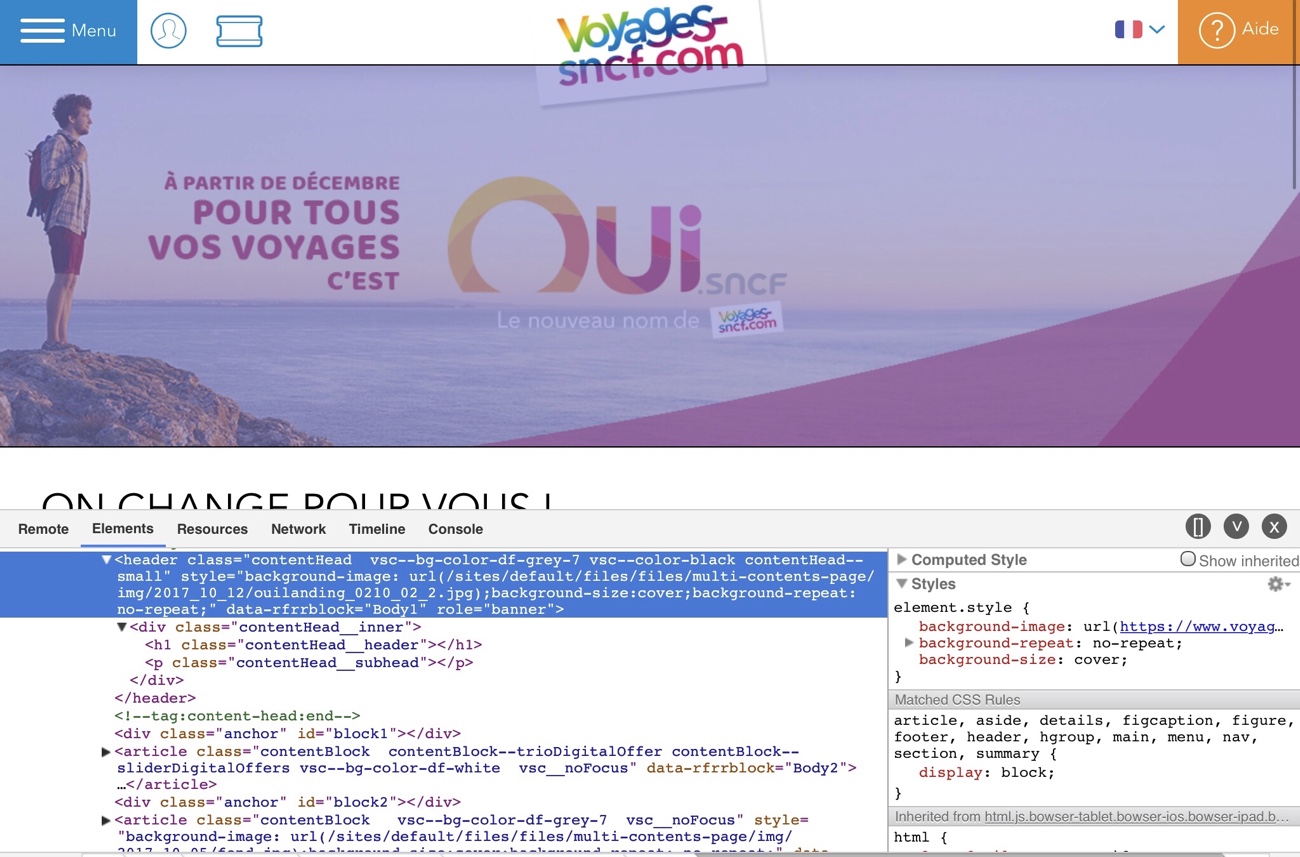
Celle-ci est chargée en background CSS, alors qu’il s’agit bien d’une image de contenu ici puisqu’elle contient du texte destiné à l’utilisateur. C’est pourquoi il semble y avoir à l’intérieur des balises de texte, sans doute masquées, prévues à cet effet mais qui ne sont malheureusement pas remplies.
Du coup, pas d’image, pas d’information.
Et même si ça n’a pas un impact significatif, c’est aussi utile pour le SEO.
Et puis, c’est même la règle nº1 des bonnes pratiques Opquast.
Mieux: Balise alt stylisée
Maintenant partons du principe que votre image ne se charge pas.
Du coup le texte alternatif va s’afficher avec le style par défaut de votre page ou du parent, ce qui ne sera peut être pas en accord avec votre design.
L’idée est donc de styliser l’affichage du texte alternatif des images. Il s’agit pour cela d’appliquer quelques propriétés CSS liées au texte de manière à lui donner le style le plus approprié par rapport à la place qu’a l’image dans le contenu de votre page.
Si votre image contient du texte en gros caractères parce qu’il s’agit de la mise en avant d’une promo comme oui.sncf par exemple.
XHR
Bien: Gérer les erreurs
C’est cette partie qui m’a amené principalement à écrire sur ce sujet.
Bien trop souvent les requêtes XHR sont exécutées via un snippet copié-collé depuis une page ou document qui montrait un vague exemple basique et sont peu ou pas configurées.
Elles se contentent alors de ne gérer qu’un seul et unique cas: celui où tout va bien.
Entre vous et moi, on en serait pas à la 3ème section de cet article si tout se passait comme prévu. Et la requête XHR est probablement celle où l’on a le plus de contrôle ce qui est dommage de s’en passer.
Commençons par le callback de success: si une autre erreur survient côté serveur, et que vous l’avez géré en renvoyant une réponse appropriée, vous devez alors le prendre en compte et afficher un message d’erreur sur votre page.
Un utilisateur sera moins frustré par une notification d’erreur suffisamment explicite plutôt que par l’impression que rien ne s’est passé ou que ça s’est passé mais que ça n’a au final pas fonctionné correctement.
Il s’agit donc du cas où vous renvoyez une erreur « normale » (par exemple, une inscription où le mail spécifié existe déjà en base de donnée).
Maintenant il y a le cas où votre serveur renvoie un code HTTP d’erreur comme 404, 500, etc.
Dans ce cas là, soit vous utilisez une librairie/framework/helper et vous devez appliquer un comportement spécifique dans le callback d’erreur, soit vous gérez le cas où le code de la réponse n’est pas 200.
La bonne pratique alors est déjà d’interrompre tout comportement temporaire (zone masquée, affichage d’image animée de chargement, etc.) puis d’indiquer qu’une erreur s’est produite.
Vous pouvez préciser un code d’erreur en fin de message et idéalement un lien vers la page contact. De cette façon, l’utilisateur pourra peut-être vous signaler l’erreur, ce qui pourra vous aider à la corriger si vous ne l’aviez pas repérée.
Mieux: Annuler la requête précédente, mettre un timeout et annulation manuelle
Si vous avez déjà tout fait de la section précédente, vous avez fait 90% du travail.
Pour la suite, prenons l’exemple d’un moteur de recherche dont les résultats sont chargés de manière asynchrone. Vous cochez un élément dans les facettes, les résultats se rafraîchissent sans rechargement complet de la page.
Vous cliquez alors sur un nouveau filtre, ce qui lance une requête, puis immédiatement sur le suivant puisque vous souhaitez en avoir plusieurs actifs en même temps.
Malheureusement dans la plupart des cas, une requête va se lancer au premier filtre, puis une autre pour le second filtre. Vous allez alors avoir deux requêtes tournant simultanément, et si la seconde se termine avant la première, vous n’aurez même pas le résultat attendu une fois tout chargé.
C’est pour cette raison que lorsque vous lancez une requête, il faut penser à la stocker de manière à pouvoir l’annuler si une autre est lancée. De cette manière, la première requête étant devenue inutile, vous évitez les risques d’erreur d’affichage et les ralentissements de traitement des requêtes.
Ensuite, pour des requêtes que vous savez généralement rapides, il peut être utile de mettre en place un timeout à la requête afin que celle-ci s’annule d’elle-même au cas où son temps de traitement est anormalement long.
Une autre bonne pratique qui relève plutôt du bonus: il peut être utile de mettre un bouton d’annulation manuelle de la requête pour celles que vous savez potentiellement longues et non transactionnelles (sauf si vous avez correctement géré les soumissions de doublons potentiels côté serveur).
Enfin, parmi toutes ces bonnes pratiques, que ce soit « annuler la requête » ou « afficher un message d’erreur », cela signifie que vous allez revenir en arrière. Pensez alors à enlever votre loader, remettre le lien qui permet de lancer la requête ou décocher la case qui était liée au filtre qui vient d’être coché.
Appels WS/API
Bien: catcher et logger les erreurs
Passons maintenant à une partie qui concerne d’avantage la partie serveur (car de mon point de vue, c’est de ce côté que c’est le plus simple à mettre en place).
Les appels de Webservices ou d’API côté serveur sont au final assez similaires aux appels XHR que vous faites en front et sont sujets aux mêmes types d’erreurs: renvoi d’une erreur « normale », coupure réseau, endpoint inaccessible, etc.
Admettons que vous vous attendiez à recevoir du JSON, et que pour une raison inconnue l’API se mette à vous renvoyer une erreur serveur en texte brut. Vous vous retrouvez alors avec une erreur de votre côté et dans l’impossibilité de continuer le traitement normal de votre script.
Pour peu que vous n’ayez pas géré ce cas, c’est probablement toute votre application qui risque d’être inutilisable et donne à l’utilisateur l’impression que votre application est mal développée et diminue le niveau de confiance qu’il a en celle-ci.
Il vaut faut alors catcher le cas où il y a une erreur anormale puis renvoyer une réponse appropriée (message d’erreur).
Ensuite, contrairement au frontend où c’est plus difficile à faire, vous pouvez logger cette erreur dans un fichier spécifique afin d’être alerté du problème, investiguer d’avantage et éventuellement améliorer votre code pour mieux répondre à ce type de cas quand il se présente.
Si vous utilisez une librairie comme Guzzle en PHP, il est assez facile de mettre en place un logging automatique en cas d’erreur sur toutes vos requêtes via un Log Middleware.
Mieux: Refaire un essai en cas d’erreur de connexion
Si nous restons dans le cas où le serveur distant de l’API est injoignable au moment de la requête, plutôt que d’envoyer une réponse immédiate à l’utilisateur qui relancera la requête juste après, pourquoi ne pas refaire un essai directement coté serveur ?
Si vous avez la possibilité de détecter qu’il s’agit bien d’une erreur de connexion, vous pouvez sans problème refaire une tentative, ce qui fera moins perdre de temps à votre utilisateur que si il devait attendre la réponse et la relancer lui-même.
Toujours si vous utilisez une librairie comme Guzzle, vous pouvez mettre en place un Retry Middleware.
Vous pourrez en plus définir combien de tentatives vous allez effectuer (1 ou 2 supplémentaires maximum), mais vous pouvez également définir dans Guzzle le timeout de connexion ainsi que celui d’exécution, ce qui permettra d’éviter une attente interminable si elle n’a pas lieu d’être (breaking news: elle n’a jamais lieu d’être)
Validation de formulaire
Bien : Valider le form en back
Contrairement à ce qu’on peut lire d’habitude, je ne vais pas recommander en premier une validation des formulaires côté front.
Beaucoup pensent qu’à partir du moment où ils ont empêché l’utilisateur sur leur navigateur de saisir une information incorrecte, alors tout est réglé. Sauf que ça représente déjà une grosse faille de sécurité et augmente le facteur risque de corruption des données et/ou d’exécution buguée de votre application.
Côté serveur, toute saisie effectuée par l’utilisateur doit systématiquement être contrôlée et même nettoyée.
Cela signifie par exemple que si un champ est obligatoire, on vérifie que sa valeur n’est pas vide après l’avoir nettoyé des espaces en début et fin de chaîne (trim).
Si l’on attend un nombre entier, on va supprimer les espaces inutiles (trim), forcer la valeur en entier, puis vérifier qu’elle n’est pas vide (sauf si 0 est une valeur autorisée).
Beaucoup de frameworks et CMS connus intègrent une validation semi-automatique de vos formulaires (Symfony, Laravel), ou a minima des fonctions de nettoyage (Wordpress).
Il est assez simple dans l’ensemble de mettre en place ce type de système et de le rendre réutilisable facilement dans le cas de Wordpress par exemple.
Vous pouvez ensuite coupler ça à un système de Flash Message6.
Mieux : Valider aussi en front et afficher des erreurs explicites
Maintenant que vous avez assuré l’intégrité des données envoyées côté serveur, autant prévenir l’utilisateur en temps réel lorsque sa saisie ne correspond pas à ce que vous attendez et lui dire précisément ce que vous voulez.
L’affichage de ce qui est attendu (indices de saisie) ainsi que des erreurs de saisies relève de plusieurs bonnes pratiques à appliquer que vous trouverez dans le référentiel Opquast.
Plus votre formulaire sera facile et clair à remplir plus vite il le sera, et plus vous ferez de conversions (si c’est votre formulaire de support en revanche, c’est plus embêtant).
Il faut d’abord veiller à ce que la saisie en front soit validée de la même façon qu’en back afin de ne pas avoir de disparité dans le processus de soumission du formulaire.
Valider en temps réel c’est bien, mais valider correctement c’est encore mieux:
- Le signe plus (+) dans les adresses emails, c’est valide (et c’est pratique) ;
-
Validez la robustesse d’un mot de passe par un algorithme adapté plutôt que par la présence de certains caractères (spéciaux, majuscules, etc.) ou la longueur de la chaîne ;
-
Indiquez le format attendu après le champ et insérez un exemple en placeholder ;
-
N’utilisez pas le placeholder comme label ;
Pages d’erreur personnalisées
Bien: 404 personnalisée
Une autre bonne pratique plutôt bien adoptée désormais: renvoyer une page 404 personnalisée.
Cela ne signifie pas qu’il faut juste rajouter de la couleur sur « 404 » mais plutôt que l’utilisateur n’ait pas l’impression d’être sorti de votre site. Certes l’url qu’il a saisi ne correspond pas ou plus à du contenu existant, mais il ne faut pas pour autant qu’il ait l’impression que tout le site est cassé ou que le problème vient de son côté. Après tout, il vient peut être certainement du vôtre si un lien menant vers une 404 est présent sur votre site.
Idéalement, cela signifie remettre la navigation principale du site, de façon à ce qu’il puisse retourner quelque part, le plan du site, mais aussi afficher clairement que le contenu n’existe pas ou plus sans pour autant agresser visuellement (évitez l’écran rouge avec le message en blanc par exemple).
Enfin, dans un monde parfait, ajoutez-y un formulaire de contact.
Cela peut permettre à l’utilisateur de vous contacter si il souhaite savoir où est passé le contenu désiré, si par exemple il a bougé sans qu’il y ait eu de redirection en place.
Là encore, la plupart des CMS et Frameworks permettent de mettre en place facilement une page 404 personnalisée.
Côté Wordpress cela passe par une template 404.php, tandis que sur Symfony cela passe par une template spécifique.
Même sur Jekyll c’est simple à mettre en place si vous utilisez un générateur statique, alors pas d’excuse.
Mieux: 4xx,5xx personnalisées
La page 404 peut être une erreur « normale » dans la plupart des cas, mais il existe d’autres codes d’erreurs amenés à être renvoyés sur votre site.
Pour peu que vous ayez fait une erreur quelconque dans votre code, votre site pourrait renvoyer une erreur 500 par exemple. C’est notamment le cas par défaut chez Symfony et Laravel.
De la même manière que la 404, vous pouvez alors renvoyer une page personnalisée avec le même contenu, sauf le message d’erreur bien entendu.
De cette manière, toute page d’erreur sur votre site permet à l’utilisateur de rester dans celui-ci et d’être légèrement rassuré et un peu moins frustré.
Bonus: Meta Viewport
Dans cette courte section supplémentaire, l’erreur est plutôt côté conception si votre site n’a pas été conçu en responsive ou en version mobile adaptée.
Dans ce cas, et seulement dans ce cas, pensez à intégrer une balise meta viewport avec une largeur minimum et sans bloquer le zoom (il ne doit jamais être bloqué).
Je vois encore trop souvent des sites qui n’ont pas été pensé pour le mobile et/ou responsive, mais qui ont un design fluide. Ce qui signifie que 2 colonnes à 50% de largeur sur desktop sont complètement écrasées sur mobile. Cela rend le site totalement inutilisable.
Faciliter l’utilisation au zoom est la manière la plus simple de rendre votre site utilisable sur mobile si celui-ci n’est pas responsive.
Pour conclure, quand vous concevez et développez votre site ou votre application, n’oubliez jamais que ce n’est pas parce que vous avez tout fait en pensant que tout se passera bien que tout se passera forcément comme prévu.
Pensez aux novices, aux personnes ne maîtrisant l’informatique, aux personnes âgées ou en situation de handicap. Pensez à l’environnement (réseau), au matériel utilisé ou tout simplement aux personnes qui vont penser différemment de vous.
Cela ne veut pas forcément dire qu’il faut s’adapter à tout et à tout le monde (quoique), mais limiter la frustration limitera la perte d’efficacité. De même que tous vos utilisateurs devraient pouvoir accéder au même niveau d’information quelque soit la méthode employée (desktop, mobile, clavier, lecteur d’écran, connexion limitée, etc.).
Pour aller plus loin et élargir un peu le sujet, je vous recommande:
- La conférence donnée par Geoffrey Crofte à Paris Web 2017 sur le sujet « Améliorer la performance: entre réalité et perception »
-
L’article de Stéphanie Walter sur sa conférence à Smashing Conference Barcelone qui avait pour sujet « Améliorer l’experience utilisateur grâce à la perception de la performance »
-
Cet article est avant tout orienté « développement » mais les autres profils les plus curieux pourront s’y intéresser également puisque cela peut aussi toucher la conception et le design. ↩
- Tableau provenant de https://developers.google.com/web/updates/2016/02/font-display ↩
-
Notez que si le navigateur ne prend pas en charge
CSS.supports(), il y a peu de chance qu’il prenne en chargefont-display↩ - Specification W3C: http://w3c.github.io/html/semantics-embedded-content.html#alt-text ↩
- Au moment de la rédaction de cet article, novembre 2017] ↩
- ce type de fonctionnalité est inclus par défaut dans Symfony et Laravel. Vérifiez si la fonction n’est pas déjà présente dans votre framework/CMS avant d’opter pour une librairie tierce] ↩